

SMYS 4 | From Win List to Win-Loss Gap: Building the Propensity Layer
Why Jai Toor stopped running signal work on wins alone and built a Claude Code workflow on the win-loss gap, compressing a month and $2,000 into 30 minutes and $10


👋 Hi, it’s Rick Koleta. Welcome to GTM Vault - a breakdown of how high-growth companies design, test, and scale revenue architecture. Join 26,000+ operators building GTM systems that compound.
This episode: Jai Toor walks through the Niche Signal Discovery skill built on top of Claude Code and DeepLine, a workflow that pulls wins and losses from HubSpot, mines the differential signal between them, and exports a verified-lead outbound campaign into Lemlist end-to-end from a single terminal. The system compresses a month of manual propensity work and nearly two thousand dollars of enrichment spend into thirty minutes and under ten dollars. The breakdown below maps the build back to the Revenue Architecture.
The Signal Commoditization Gap
Most GTM teams run their signal layer on the same three inputs: hiring posts, funding rounds, and tech stack changes. Everyone scrapes the same sources. Everyone ingests the same data into the same enrichment pipelines. Everyone reaches out on the same week. The signal stops being a signal the moment everyone is pulling from the same place.
This is not a data gap. It is a sourcing gap. The data sits on every target’s public surface. What is missing is a method for finding which specific patterns on that surface correlate with wins, and the compute to test that against every account at a cost that makes the work economical.
Jai has spent the last year building the action layer that closes that gap. Before DeepLine, Jai spent five years on growth at Uber, then built data and product at Capchase, Datafold, and VeriShop. He co-founded DeepLine, an integration layer that sits underneath the agent and handles every API call in a signal workflow through pay-as-you-go credits. He sits at the intersection of growth engineering and data infrastructure, which is exactly where this problem lives.
In this episode, Jai walks through the full build. First, the Niche Signal Discovery skill running inside Claude Code. Then the infrastructure layer that makes the skill possible: DeepLine’s connectors to HubSpot, Lemlist, and every data source the workflow needs to reach. The argument for why this is architecture and not a tool is that the same shape runs at every layer of the signal stack once the context layer exists underneath.
The Win-Loss Foundation: Why Most Signal Work Starts in the Wrong Place
Jai’s first structural point is that most signal discovery runs on the win list. Take closed-won accounts, find the common keywords on their websites, target more accounts that look like them. The output is generic ICP work dressed up as signal discovery. Everyone selling to consumer fintech will find “fintech” on the website. That is a description, not a signal.
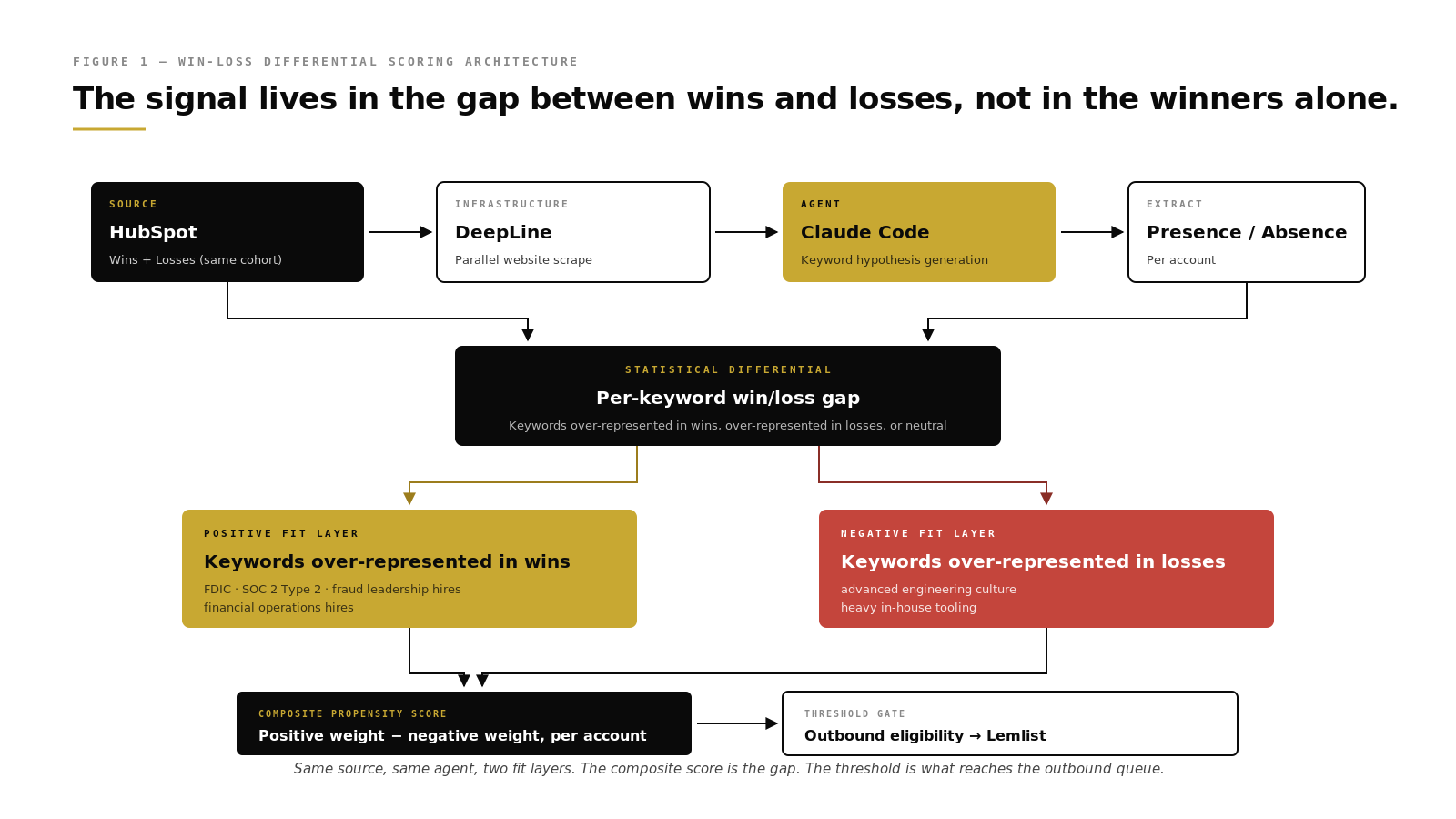
Jai inverts that. The workflow pulls wins and losses from HubSpot together, not just wins. Both cohorts are accounts the team engaged. Both cohorts were qualified enough to reach opportunity stage. The difference between them is the real selection criterion the market is using, whether the team designed it or not.
In the cybersecurity case walked through on the episode, the dataset was seventy-four deals. Wins and losses combined. Claude Code scraped the customer websites of every account on that list, generated keyword hypotheses programmatically, tested them against the scraped content, and surfaced the keywords that separated wins from losses. The positive signal for that ICP was FDIC mentioned on the company website. Specific. Testable. Almost certainly a consumer fintech company with regulated retail deposits.
The previous version of this model had used “open an account” as the proxy for the same concept. Directionally correct. Categorically worse. The specificity of the surfaced keyword is the difference between a signal that compounds and one that decays into a category filter.
Accounts that differentiate cleanly between wins and losses are the only accounts worth running downstream signal monitoring on. Everything else produces noise in the outbound queue.
The Differential Signal Layer: Positive and Negative Fit
The other half of the architecture is the negative signal layer. Most scoring systems only reward positive fit. Keywords that correlate with wins get a positive score and everything else gets ignored. Jai’s system builds both sides.
Two examples from the episode. SOC 2 Type 2 compliance on the target’s website was a positive for B2B buyers. Intuitive. The counterintuitive one was advanced engineering culture with heavy in-house tooling. Engineering-dense companies often look like good prospects on paper because they have the technical maturity to evaluate the product. The model surfaced the pattern that they close less frequently because they tend to build rather than buy.
The consequence of running only positive fit is that the BDR team spends its time on accounts that look like wins but behave like losses. One of the enterprise customers in Jai’s data had been spending 44% of their opportunity time on bad-fit accounts. Not because the BDRs were unskilled. Because the scoring model had no way to surface the structural signals that kept those accounts from closing.
Fix the negative signal layer, reclaim the 44%, and close rate moves 15 to 17 percentage points before anything else changes.
The Niche Signal Discovery Skill: One Command, End-to-End
With the scoring architecture in place, the actual skill runs from the terminal. One command. End-to-end execution.
The agent pulls every won and lost deal from HubSpot through DeepLine. It scrapes the customer websites in parallel. It generates keyword candidates from the scraped content, tests each candidate against the win and loss pools, and scores the ones that differentiate. It builds the composite propensity model. It runs the model against a hundred unqualified target accounts pulled from the enrichment source, scores them, and drops the top tier into a Lemlist campaign with verified emails and generated first-line personalization.
The output is a markdown doc. Five takeaways. A signal model with positive fits and negative fits, each scored. A hundred verified leads exported into Lemlist, with sequence copy generated, sender deliberately unattached so the operator has to confirm before the send.
Human in the loop at the send step is intentional. Every agent in Jai’s stack gets a confirmation gate before any external action fires. The Lemlist sender is unattached by default. The email drafts wait for approval. The CRM sync confirms before writing. This is the trust-building layer that gets skipped most often, and the one that determines whether a team keeps using the system after the first misfire or abandons it.

The Compression: Why Bespoke Enrichment Beats Off-the-Shelf
Jai ran this exact workflow manually for the same cybersecurity customer about six months before Claude Code and DeepLine made the end-to-end version possible. The comparison is the case for the architectural shift.
The manual version took over a month. It cost nearly $2,000 in enrichment spend. The team had to sit together and hypothesize roughly forty candidate keywords, then pay for AI to extract each one from every website in the dataset, then manually figure out which of the forty actually mattered. Most did not.
The current version runs in under thirty minutes and under $10. The keyword hypothesis step, which was the unscalable manual bottleneck, is now generated by Claude Code based on the content the agent reads. The extraction runs through DeepLine. The scoring runs in the same session. The outbound campaign writes itself into Lemlist at the end.
$2,000 to $10. One month to thirty minutes. Same outcome. Different infrastructure.
The output is not marginally better than the manual version. It is more specific. The manual version surfaced “open an account” as the proxy for consumer fintech. The current version surfaces FDIC. That specificity compounds at every downstream step: the outbound filter is tighter, the copy is more pointed, the reply rates move. Reply rates on campaigns running on Jai’s signals land at roughly 2x the baseline. A CPG customer who flipped from scraping retail websites to scoring every company with a store locator saw the same 2x lift on cold email and LinkedIn. An enterprise customer saw 15 to 17 point higher close rates once the negative-signal layer was active.
The enabling variable is Claude Code plus DeepLine. Jai’s not writing production infrastructure code to build this. DeepLine handles the API integrations through pay-as-you-go credits. Claude Code handles the orchestration. The bottleneck moves from engineering execution to problem specification. What are we optimizing for, and what does “won” actually mean in the context of this business.
The Adoption Curve: Who Is Actually Building This
The BDR function is not disappearing. It is being redeployed.
Two patterns show up in Jai’s customer base. The first is larger BDR teams with higher per-rep ROI. A BDR who used to touch 20 accounts a day is now touching 40 to 80. The raw information gathering that used to fill the calendar is gone. The rep spends the reclaimed time on calls, campaigns, and multi-threading. Revenue per rep goes up and total rep count also goes up because the unit economics of hiring another BDR improved.
The second pattern is BDR removal. One PLG customer stopped using the function entirely. AEs close the qualified PLG leads plus the automated outbound flow directly. No BDR handoff in the middle. This works when the ACV is low enough that the AE motion is economical and the close is AE-friendly. It does not work in long-sales-cycle enterprise environments where the BDR still does orchestration, phone work, and multi-threading that AEs are not positioned to run.
Cold calls still work. Jai’s customers in restaurants, CPG, and data analytics are getting meaningful lift from phone outbound, including to titles that were supposed to have moved online years ago. Chief data officers and VPs of data still pick up the phone when the signal is specific enough to justify the call. The constraint is not the channel. It is whether the signal upstream of the channel is differentiated.
