

The Claude-Powered Marketing Operating System Playbook
How to build the structured business context that makes AI useful for a marketing team


👋 Hi, it’s Rick Koleta. Welcome to GTM Vault - a breakdown of how high-growth companies design, test, and scale revenue architecture. Join 26,000+ operators building GTM systems that compound.
The marketing team is using AI. Everyone is. Someone has ChatGPT open. Someone else is running Claude in a browser tab. The agency is generating LinkedIn posts that sound like every other LinkedIn post. Output volume is up. Quality is uneven. Brand voice drifts every time a different person prompts a different model on a different day.
This is not an AI problem. It is a context problem.
The teams getting compounding output from AI are not using better models. They are feeding the model better context, structured the same way every time, queryable on demand. Everyone else is reprompting from scratch and calling that a workflow.
A Marketing Operating System fixes this. It is a centralized repository of the company’s marketing knowledge, written in a format the model can read, organized into layers that load only when relevant. One CMO can build the first version in a few weeks of evenings. The build sequence is what this Playbook covers.
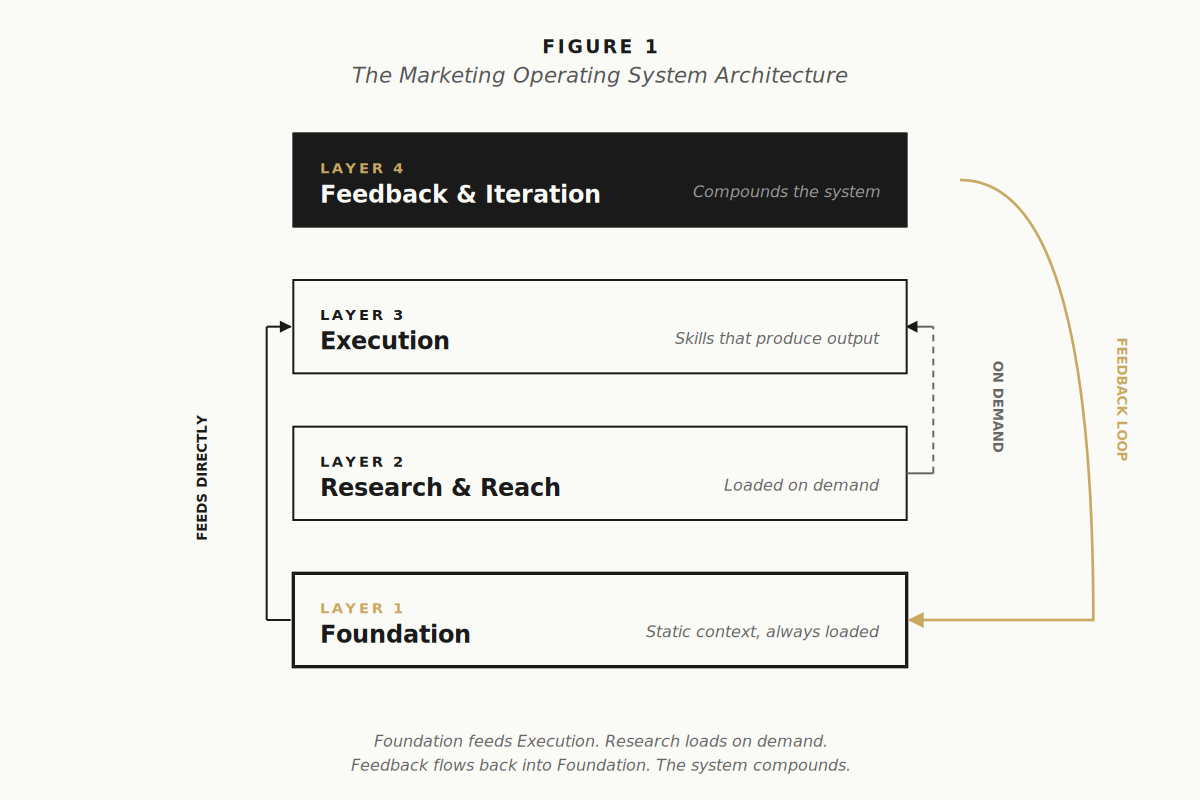
The Four Layer Model
The system has four layers. They build in order. Skipping ahead produces a system that generates fast but generates wrong.
Layer 1 is Foundation. Static context the model needs every time it produces anything: who the company is, the brand voice, the services, the ICP, the markets, the positioning, the team, the budgets. This is the layer most teams skip because it feels like documentation work, not AI work. It is the layer that determines whether anything downstream produces output worth shipping.
Layer 2 is Research and Reach. Real-time market and customer context, fed into the system through connectors when a specific task needs it. Loaded on demand, because loading everything every time clogs the model’s working memory and degrades output quality.
Layer 3 is Execution. The skills the system can perform: campaign briefs, blog drafts, LinkedIn posts, case studies, decks, press releases. Each skill reads from Foundation, optionally pulls from Research, and produces in a format the team can edit and ship.
Layer 4 is Feedback and Iteration. The mechanism that turns the system from a drafting tool into a compounding asset. Every output gets reviewed, the edits get captured, the patterns get fed back into Foundation.
Most teams stop at Layer 3 and wonder why the output stays generic. The system compounds at Layer 4 or it does not compound at all.
Layer 1: Build the Foundation
The Foundation is a set of markdown files in a single repository. Markdown because it is plain text, version controllable, readable by every model, editable by anyone who can use a text editor. Not Notion. Not Google Docs. Not a Confluence page. Markdown files in a repo.
The Foundation contains, at minimum: a company overview, a brand voice and tone guide with examples of accepted and rejected phrasing, a services or product catalog with positioning for each, an ICP document for each segment with named buyer roles and their priorities, a market and competitive landscape document, a team roster with roles and approval authority, and a current-quarter priorities document that names what the marketing team is being measured on.
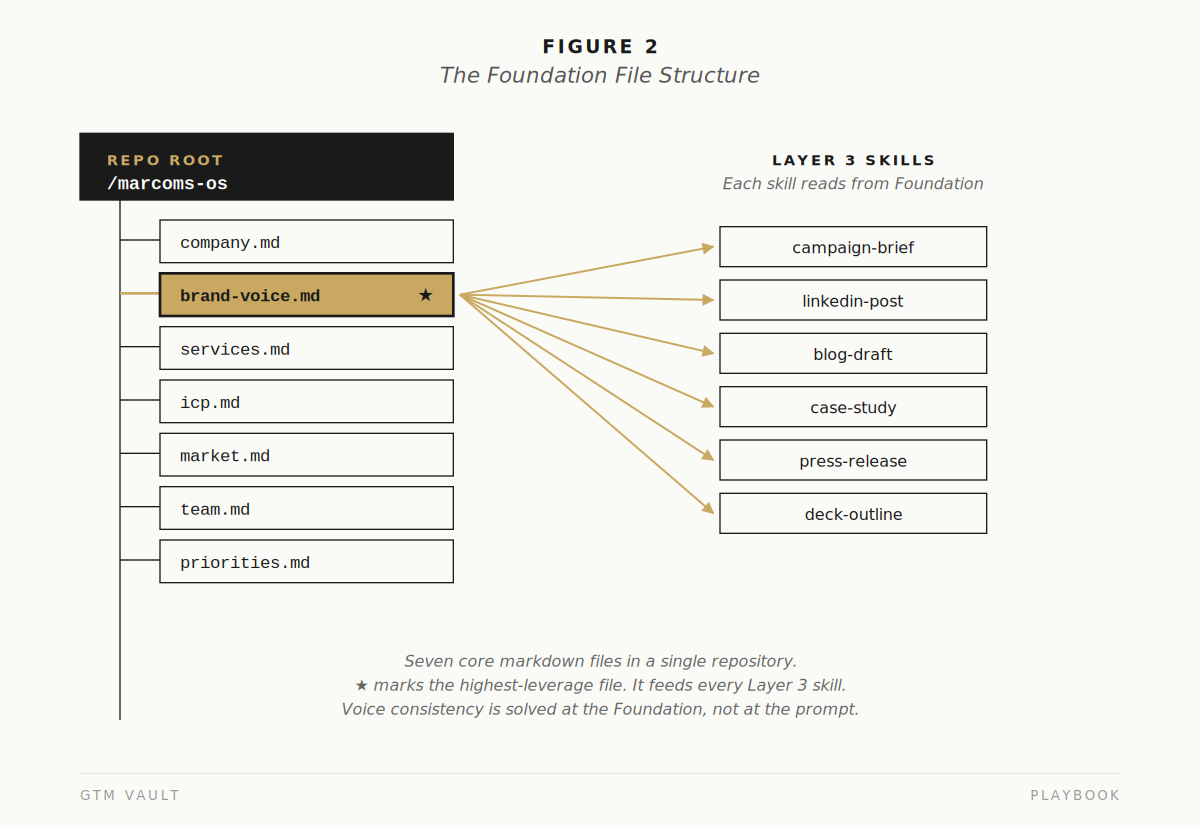
The brand voice document is the highest-leverage file in the entire system. It should not be a list of adjectives. Adjectives like “bold” and “approachable” produce nothing useful when the model reads them. The document needs concrete examples: three sentences the brand would write, three it would not, and the structural reason for each. The model learns voice from contrast, not from descriptors.
The build sequence for Layer 1 is four to six weeks of evenings if one person is doing it and the source material already exists in some form. If it does not, the work is longer, but the work was needed regardless. A marketing team without a written brand voice was already producing inconsistent output. The Foundation just makes the gap visible.
Layer 3: Build Execution Before Layer 2
The natural instinct is to build the layers in order. Foundation, then Research, then Execution, then Feedback. The natural instinct is wrong.
Build Layer 3 before Layer 2. Execution skills running on Foundation alone produce output that is on-brand but generic. That is the right output to start with. It exposes which Foundation files are thin, which voice rules the model misinterprets, and which skills the team actually uses versus the ones that sounded important in planning. Adding Research before the base system is stable adds variables before the system can absorb them.
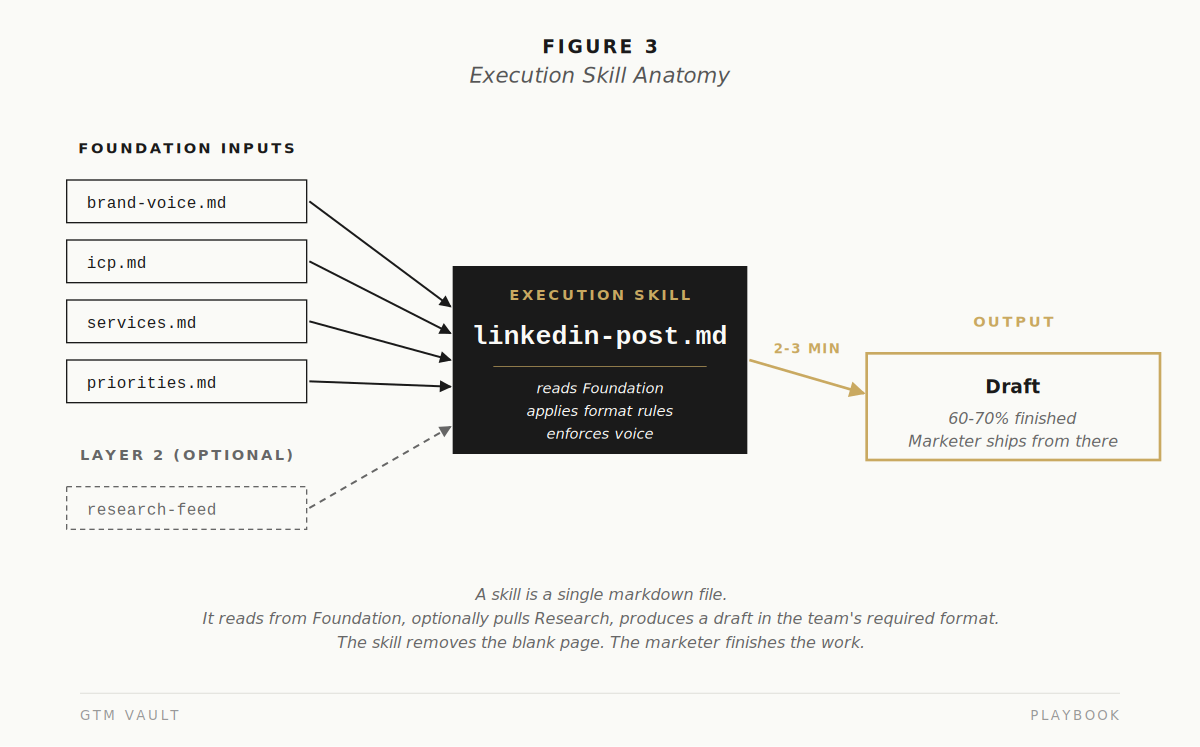
A first batch of Execution skills is four to six. A campaign brief generator. A LinkedIn post generator that follows the brand voice rules. A blog draft generator with a defined structure. A case study generator that reads from a customer template. A press release generator. A deck outline generator. Each one is a markdown file that tells the model how to read the Foundation, what format to produce, and what rules to follow.
The team should invoke any skill, get a draft in two to three minutes, and have a 60 to 70 percent starting point an experienced marketer can finish. The skill is not replacing the marketer. It is removing the blank page.
Layer 2: Add Research When the Generic Limit Is Hit
Once the team has used Layer 3 skills for a few weeks, the limits of Foundation-only output become specific and obvious. The campaign brief skill produces a strong structure but cannot speak to current competitor positioning. The blog skill writes well but does not know what the audience searched for last month. These specific gaps are the prompts to build Layer 2.
Layer 2 connectors pull live data into the system on demand. Search trend data. CRM deal context. Customer interview transcripts. Competitor content tracking. Each connector is added because a specific Layer 3 skill needs it for a specific reason. None of it loads by default.
The discipline at Layer 2 is restraint. Loading everything every time is the most common failure. The model has a finite working window. Every irrelevant file in the context dilutes the relevant ones. The architectural rule: load the minimum context required to produce the specific output, and no more.
Layer 4: The Feedback Loop That Makes the System Compound
Layer 4 is the layer most teams never build. It is also the layer that separates a drafting tool from an operating system.
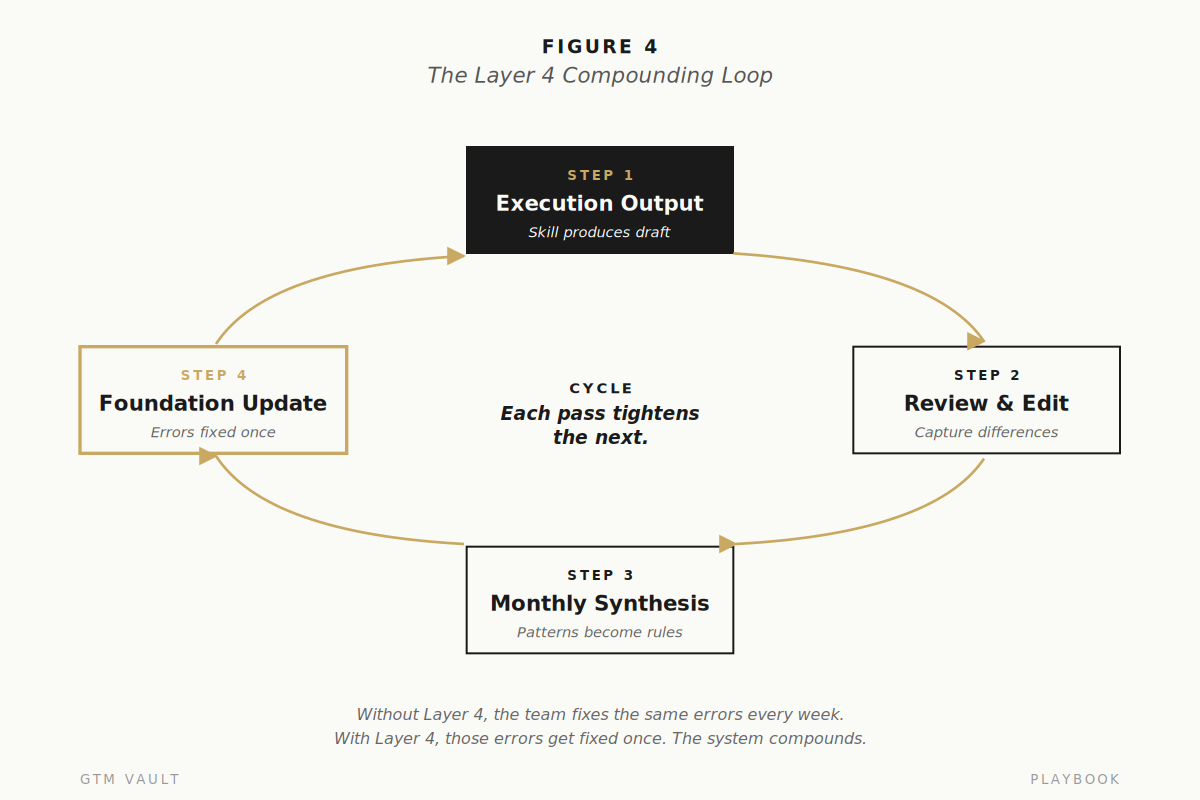
The mechanism is straightforward. Every output the system produces gets compared against the final version that shipped. The differences are captured. The patterns are reviewed monthly. The Foundation files are updated to reflect what was learned.
If the LinkedIn skill consistently produces opens that are too long, the brand voice file gets a sharpened rule about opening length. If the case study skill keeps formatting outcomes wrong, the case study template gets updated. The system improves because the corrections are codified, not because the next prompt is better.
Without Layer 4, the team fixes the same model errors every week. With Layer 4, those errors get fixed once.
What This Costs to Build
A first usable version takes one builder, four to eight weeks of evenings, the documentation the company already has in some form, and a Claude subscription. No platform to buy. No vendor to onboard. The builder does not need to code. They need to write structured markdown and test outputs against what the team would actually ship.
The work that takes the longest is not the technical work. It is forcing the company to write down what was previously in three people’s heads. That work was always overdue. The Marketing Operating System is the forcing function.
The Real Moat
The model is a commodity. Every team has access to the same one. The team that wins is the team whose model is reading the most accurate, most current, most specifically structured business context.
The moat is not the AI. The moat is the Foundation. The team that codifies its positioning, its voice, its ICP, and its priorities into a system the model can read on demand has a multiplier on every piece of output it ships. The team that does not is producing the same generic content as every competitor with a ChatGPT subscription.
Within a year this will not be a competitive advantage. It will be the baseline. The leaders who start now build the Foundation while the work is still differentiating. The ones who wait will build it under pressure when the gap is already visible in the pipeline.
The Foundation is the work. Start there.